本期由南昌大学第一附属医院彭德昌团队 段文峰 医师分享Arman Eshaghi等人2018年发表在nature communication(影响指数:12.121)的一篇题为:“Uncovering the heterogeneity and temporal complexity of neurodegenerative diseases with Subtype and Stage Inference”的文章。

神经退行性疾病的异质性是理解疾病和治疗发展的一个关键障碍,因为研究队列通常包括不同疾病轨迹的多种表型。在这里,我们介绍了一种机器学习技术--亚型和分期阶段推断(SuStaIn)--能够从广泛可用的横断面病人研究中发现具有不同时间进展模式的数据驱动的疾病表型。两种神经退行性疾病的成像研究结果揭示了亚群及其区域神经退行性的不同轨迹。在遗传性额颞叶痴呆症中,SuStaIn仅从成像中就能识别基因型,验证了其识别亚型的能力;此外,该技术还揭示了基因型内的异质性。在阿尔茨海默病中,SuStaIn发现了三种亚型,独特地描述了其时间上的复杂性。SuStaIn提供了精细的病人分层,与忽略亚型(p = 7.18 × 10-4)或时间阶段(p = 3.96 × 10-5)的标准模型相比,它大大增强了预测诊断类别之间转换的能力。SuStaIn为实现疾病亚型发现和精准医疗提供了新的希望。
神经退行性疾病,如额颞叶痴呆(FTD)和阿尔茨海默病(AD),具有生物异质性,导致体内疾病生物标记物的差异很大,例如成像的体积测量、腰椎穿刺术的蛋白质测量或心理计量学的行为测量,这降低了它们在疾病研究和管理中的效用。这种异质性的关键因素是,个体属于一系列疾病亚型(导致表型异质性),并处于动态疾病过程的不同阶段(产生时间异质性)。以前旨在解释生物标记物差异的研究通常集中在这种异质性的一个方面:粗略的表型异质性,通常是疾病晚期的表型异质性,或者广泛人群中的时间异质性。然而,无法将亚型的范围从每种亚型的发展和进展中分离出来,限制了这些技术所能提供的生物学洞察力,以及它们对患者分层的效用。构建一幅分离表型和时间异质性的综合图景,即确定不同的亚型并表征每一种亚型的发展和进展,仍然是当前的主要挑战。然而,这样的图片将提供对潜在疾病机制的洞察,并使准确的细粒度患者分层和预测成为可能,从而促进临床试验和医疗保健中的精准医学。
FTD和AD在病理、遗传和临床上均表现出明显的异质性。在FTD中,很大一部分(约三分之一)病例是在常染色体显性基础上遗传的,最常见的原因是原颗粒蛋白(GRN)、微管相关蛋白tau(MAPT)和9号染色体开放阅读框72(C9orf72)突变。在主要遗传组中,GRN突变与TDP-43 A型病理有关,MAPT突变与tau包涵体相关,C9orf72与A型或B型TDP-43病理相关1。相反,AD具有单一的病理特征:同时存在淀粉样斑块和神经原纤维缠结,常染色体显性病例的比例要小得多,仅占病例的1%至6%2。在AD中观察到的病理异质性包括神经原纤维缠结的分布的变化,死亡时25%的患者在尸检中有不典型的神经原纤维缠结分布(描述为海马体或边缘占优势)3。FTD和AD都表现出不同的临床症状。FTD既有行为表现,也有语言表现,在遗传性FTD中,临床症状可进一步包括非典型帕金森症和肌萎缩侧索硬化症。在AD中,主要的临床综合征被广泛地分为遗忘型和较罕见的非遗忘型变异型,非遗忘型变异型包括语言变异型AD、对数进行性失语症、视觉感知变异型AD、后皮质萎缩和额叶变异型AD4。
以往对神经退行性疾病异质性的研究集中在时间异质性(即受试者在不同疾病阶段表现不同)或表型异质性(即不同组受试者即使在同一疾病阶段也表现不同),但很少两者兼而有之。我们将这两种方法称为只考虑时间异质性但不考虑表型异质性的阶段模型和考虑表型异质性但不考虑时间异质性的仅亚型模型。仅阶段性模型产生于例如对疾病阶段的回归5,6和数据驱动的疾病进展模型7-15。尽管这样的模型能够更深入地理解一系列疾病的时间进展,但固有的假设是所有人都有单一的表型,即遵循大致相同的轨迹,这是一个关键的限制。充其量,这限制了它们所能提供的生物学洞察力和分层的准确性,但也可能导致错误的结论。例如,仅用子类型的模型使用集群(例如,参考文献。16-23)以识别不同的群体,或使用与模型无关的信息对个体进行分组,例如遗传学(例如,参考文献24)或尸检(参考文献25-28),用于基于活体成像的模型。对于典型的仅限亚型的模型,限制是固有的假设,即所有受试者都处于共同的疾病阶段,因此队列没有时间异质性。这需要对个体进行先验的分期和选择,这在实践中通常是粗暴的,留下了不特定于亚型差异的模型。先前已经为一小部分常染色体显性遗传的神经退行性疾病构建了疾病亚型和阶段异质性的模型。例如,Rohrer等人29通过将成像标志物与估计的发病年龄(来自家族史)进行回归,研究遗传组内的时间异质性。然而,这类研究缺乏识别基因组内表型的能力,而且恢复的基因型进展模式的时间分辨率受到先验分期的不准确性的限制。
本文介绍了亚型和阶段推断(SuStaIn):这是一种计算技术,它可以分解时间和表型的异质性,以确定具有共同疾病进展模式的人群亚群。我们使用来自遗传性FTD和AD患者队列的结构性磁共振成像(MRI)数据集来证明SuStaIn。在每个案例中,SuStaIn都提供了一个数据驱动的分类法(一组亚型和阶段),以及每个数据驱动的亚组中神经变性进展的详细图片。从遗传性FTD的数据集中,SuStaIn仅从成像上就能确定与基因型密切相关的亚型,并重建反映个别基因组分析的神经变性模式。这验证了SuStaIn识别具有不同时间进展模式的亚型的能力,因为已知不同的基因型具有不同的神经变性模式,在MRI中可见脑萎缩29。然而,SuStaIn进一步发现C9orf72基因突变的携带者有两种不同的基因型内表征,而发现MAPT和GRN突变组更具有同质性。在AD中,SuStaIn确定了三种不同的亚型,并重建了它们以前未见过的时间进展。在这两种神经退行性疾病中,我们证明了个体对SuStaIn亚型的强烈分配,这与文献中仅有的亚型模型(如参考文献23)相反。即使在非常早期的阶段,至少有一部分个体显示出与特定亚型的强烈一致性,这突出了其在精准医疗中的潜在效用。在AD中,我们表明SuStaIn亚型和阶段增强了预测诊断类别之间转换的能力,大大超过了仅亚型或仅阶段的模型。
结果
亚型和分期推论。图1提供了SuStaIn建模技术的概念性概述。SuStaIn是一种无监督的机器学习技术,它识别具有常见疾病进展模式的人口亚组。维护建立在集群思想的基础上并将其结合在一起(例如,参考文献16-23)和数据驱动的疾病进展模型(例如,参考文献7-10,12)。这一组合独特地使SuStaIn能够对不同疾病阶段具有共同表型的个人进行分组。它确定可用数据可以支持的子类型的数量,重建每个子类型内的阶段的轨迹,并为每个受试者分配每个子类型和阶段的概率。这些特征提供了对潜在疾病生物学的洞察,以及在早期疾病阶段体内细粒度分层的机制。
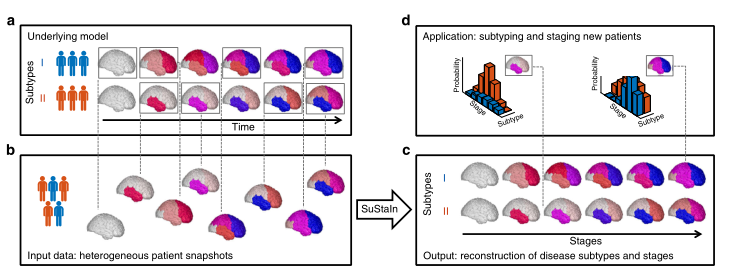
图1. SuStaIn的概念性概述。基础模型面板(a)认为患者队列由一组未知的疾病亚型组成。输入数据(输入数据面板,b),可以完全是横断面的,包含每个受试者的生物标志物测量快照,具有未知的亚型和未知的时间阶段。SuStaIn通过同步聚类和疾病进展模型恢复疾病亚型的集合及其时间进展(如输出面板c所示)。给定一个新的快照,SuStaIn可以通过比较快照和重建,估计受试者属于每个亚型和阶段的概率(如应用面板d所示)。该图描述了两个假设的疾病亚型,分别标记为I和II,生物标志物是区域脑容量,但SuStaIn很容易适用于任何标量的疾病生物标志物和任何数量的亚型。每个区域的颜色表示该区域的病理量,从白色(无病理)到红色到洋红色到蓝色(最大病理)。
合成数据。一项模拟研究(见补充方法、补充结果、补充讨论和补充图1-12)验证了维持算法的能力,该算法能够从具有与本研究中使用的对象、生物标记物和集群(子类型)类似数量的不同数据集中恢复预定义的子类型及其进展模式。
亚型进展模式。我们利用遗传性额颞叶痴呆倡议(GENFI)和阿尔茨海默病神经影像倡议(ADNI,是著名的AD(阿尔茨海默症,Alzheimer’s disease)纵向计划之一。ADNI中收录了许多AD,MCI数据,包括不同阶段的AD(如emci, lmci),不同显像剂的(如18F, 11C),不同成像技术(如PET, MRI),不同成像设备(如飞利浦Philips)的均有)的MRI数据的横断面区域脑容量,证明了SuStaIn在两种神经退行性疾病,即遗传性FTD和散发性AD中的作用。GENFI研究导致FTD的GRN、MAPT和C9orf72基因突变携带者的生物标记物变化。已知GRN和MAPT突变与不同的表型相关,而C9orf72是一个异质性组30。在这里,GENFI作为一个测试数据集,带有用于验证的部分已知的基本事实,因为我们希望ADVISE将遗传群体识别为不同的表型亚型。然而,它进一步支持了对不同基因型的表型和时间异质性的研究。具体地说,我们对GENFI(图2a)中所有172名突变携带者的联合数据集进行了维护,没有基因类型,并将产生的亚型分配和进展模式与(A)参与者的基因标签(图2B)和(B)分别从每个基因获得的亚型进展模式(补充图13;6个GRN携带者,63个C9orf72携带者,33个MAPT携带者)进行了比较。接下来,我们使用SuStaIn从ADNI(793名受试者,包括524名轻度认知障碍(MCI)或AD)中识别散发性AD亚型,并描述他们从疾病早期到晚期的进展(图3)。我们在很大程度上独立的数据集中测试了持续亚型的一致性——ADNI 1.5T MRI(576名受试者,包括396名MCI或AD患者)扫描(图4),而不是图3中使用的主要3T数据集。在每种疾病中,交叉验证测试亚型的重复性和估计的进展模式(补充图14)。

图2 SuStaIn利用GENFI数据对遗传性额颞叶痴呆进行建模。a SuStaIn确定的四种亚型的进展模式。每个进展模式由一系列阶段组成,其中突变携带者(有症状和无症状)的区域脑容量相对于非携带者达到不同的z-cores。直观地说(更精确的描述见方法:不确定性估计),在每个阶段,每个区域的颜色表示体积损失的严重程度:白色为未受影响;红色为轻度影响(z-core为1);品红色为中度影响(z-core为2);蓝色为严重影响(z-core为3或以上)。标有A的圆圈表示每个亚型在每个阶段的萎缩模式的不对称性(左右半球体积之差的绝对值除以左右半球的总体积)。CVS是模型的交叉验证相似度(见方法:两个进展模式之间的相似度):亚型进展模式在交叉验证褶皱中的平均相似度,范围从0(无相似度)到1(最大相似度)。f是估计属于每个亚型的参与者的比例。计算方法是:在个体属于某一亚型的情况下,个体具有某一特定基因型的概率。
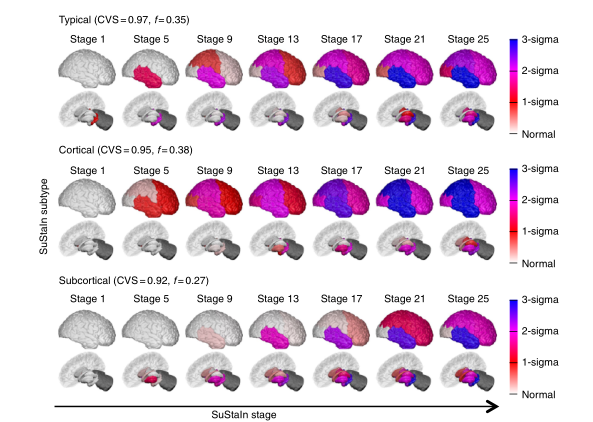
图3 利用ADNI数据对散发性阿尔茨海默病进行SuStaIn建模。行中显示了SuStaIn确定的三种亚型的进展模式。图为图2,但Z值是相对于淀粉样蛋白阴性(脑脊液Aβ1-42>192 pg/ml)的认知正常受试者而言的,即脑脊液中没有淀粉样蛋白病变证据的认知正常受试者。在阿尔茨海默病的分析中,小脑不作为一个区域,所以用深灰色阴影显示。
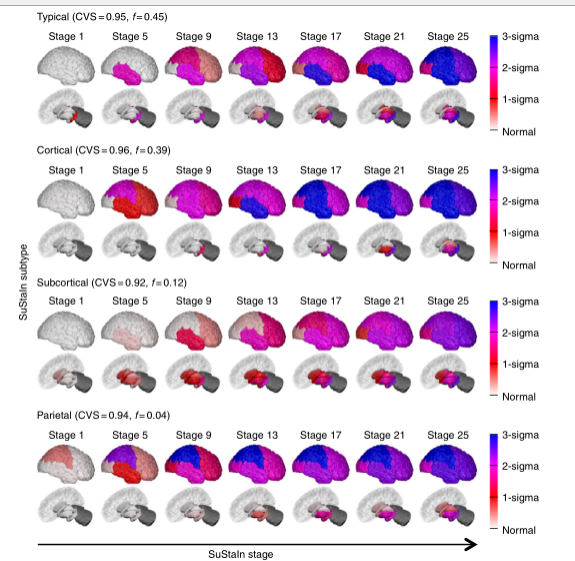
图4 图3中SuStaIn亚型的可重复性。一个基本独立的阿尔茨海默病数据集(只有59名受试者在用于生成此图的576名受试者数据集和图3中使用的793名受试者数据集中),包括那些通过1.5T MRI扫描而不是3T MRI扫描测量的区域脑容量。图表与图3相同,行中显示的是SuStaIn确定的其中一个亚型的进展模式。SuStaIn建模确定了三个主要的亚型:一个典型的、一个皮质的和一个皮质下的亚型,这与图3中的三个亚型很一致,还有一个非常小的离群组(只有4%),其亚型我们称之为顶叶型。这个小的亚组可能代表了具有后皮质萎缩表型的离群者。
在FTD中,SuStaIn揭示了基因内的表型。图2显示,在不需要事先了解基因的情况下,SuStaIn成功地识别了GENFI中不同遗传组的进展模式,并进一步表明C9orf72组的表型异质性源于两个神经解剖学亚型。图2a显示了从GENFI中所有突变携带者的全集中找到的四种亚型。我们将其称为非对称额叶亚型、颞叶亚型、额颞叶亚型和皮质下亚型。图2b显示GRN突变携带者是额叶不对称亚型的主要贡献者,MAPT突变携带者是颞叶亚型的主要贡献者,C9orf72突变携带者是额颞叶亚型和皮质下亚型的主要贡献者。这表明在C9orf72组中存在两种不同的亚型。对每个基因组分别应用Support支持这一发现,证明GRN突变携带者最好描述为单个不对称额叶亚型,MAPT突变携带者最好描述为颞叶亚型,C9orf72突变携带者最好描述为两个不同的疾病亚型:额颞叶亚型和皮质下亚型。此外,SuStaIn还在MAPT组中找到了其进展模式具有高度不确定性的附属集群。这种高度的不确定性可能阻止在对图2中的所有突变携带者应用维持时检测到该簇,因为这一少量的受试者可以通过三种可选的亚型进展模式进行足够的建模。补充图13显示,每个遗传组的亚型进展模式与在所有突变携带者的全套中发现的亚型进展模式很好地一致(图2a)。补充图14A显示,图2a中估计的四个亚型在交叉验证下是可重现的,每个亚型的交叉验证折叠之间的平均相似性>93%。总而言之,这些结果有力地验证了SuStaIn从不同的数据集中恢复不同的亚型及其进展模式的能力,同时将C9orf72组的异质性分离为两个不同的亚型。
SuStaIn确定了AD的三种亚型进展模式。图3显示了SuStaIn从ADNI识别的三种神经解剖学亚型的时间进程,我们称之为典型的皮质和皮质下。SuStaIn显示,对于典型的亚型,萎缩开始于海马体和杏仁核;对于皮质亚型,开始于伏隔核、岛核和扣带核;对于皮质下亚型,开始于苍白球、壳核、伏隔核和尾状核。补充图14B显示,这三个亚型在交叉验证下是可重现的,每个亚型的交叉验证折叠之间的平均相似性>92%。
AD子类型在独立数据集中是可重现的。图4显示,图3中的三个亚型在很大程度上独立的数据集(共同的受试者<5%)中是可重现的,该数据集由来自1.5T而不是3T MRI扫描的区域脑体积组成。从1.5T数据中,SuStaIn广泛复制了3T数据中发现的三个主要星团,再次发现了典型的皮质和皮质下亚型。每种亚型的萎缩起源与3T数据基本一致:典型亚型的萎缩始于海马体和杏仁核,皮质亚型的萎缩始于脑岛和扣带状;皮质下亚型的萎缩始于苍白球、壳核和尾状核。与3T数据的主要不同之处在于,在皮质和皮质下亚型的1.5T数据中,伏隔核不被指示为萎缩的早期区域。在1.5T数据中,SuStaInt还识别了一小部分(4%)具有顶层亚型的异常值。
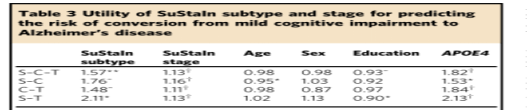
疾病亚型和分期。我们调查了在每种神经退行性疾病(图5)中维持可靠分层的能力,以确定同质队列识别的可能性。首先,我们评估了持续治疗如何可靠地将患者分配到不同的亚型(图5A,b)。具体地说,在遗传FTD中,我们测试了症状突变携带者中不同基因类型的持续亚型的一致性(表1),并将这种一致性与不考虑时间异质性的模型进行了比较(表2)。其次,我们通过与临床诊断类别的比较,评估了每种疾病维持阶段的可靠性(图5C,D)。在有临床随访信息的ADNI中,我们通过确定维持亚型和/或分期是否改变了诊断类别之间的转换风险,进一步检查了维持亚型和分期预测相关结果的能力(表3)。
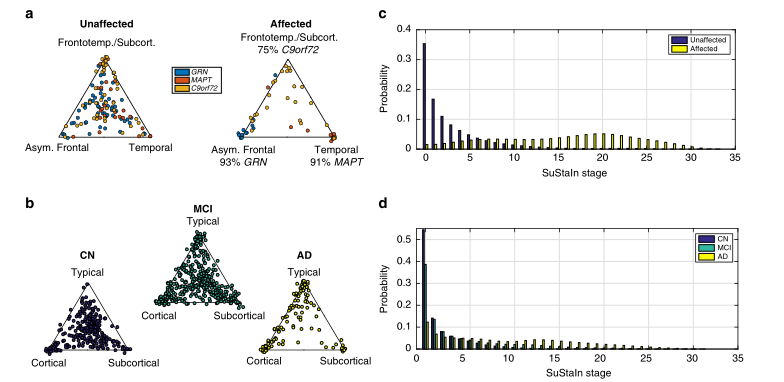
图5 SuStaIn对遗传性额颞叶痴呆和阿尔茨海默病的亚型划分和分期。a, b SuStaIn对遗传性额颞叶痴呆和阿尔茨海默病估计的疾病亚型的可分配性。每个散点图直观地显示了每个人属于SuStaIn对遗传性额颞叶痴呆(如图2a所示)和b.阿尔茨海默病(如图3所示)估计的每个亚型的概率。在三角形散点图中,每个角对应的是属于该亚型的概率为1,其他亚型为0;三角形的中心点对应的是属于每个亚型的概率为1/3。c, d 每个诊断组的受试者属于c遗传性额颞叶痴呆和d阿尔茨海默病的SuStaIn各阶段的概率。CN=认知正常;MCI=轻度认知障碍;AD=阿尔茨海默病

每一行显示不同的Cox比例危害模型的危害比,该模型利用ADNI数据估计从轻度认知障碍转化为阿尔茨海默病的风险。每一列显示每个变量的估计危险比。每个危险比都告诉你某个特定变量每增加一个单位,转换的风险如何变化:比值为1意味着风险没有改变,比值>1意味着风险增加,比值小于1意味着风险减少。对于第一个模型(S-C-T),假定危险比从皮层下亚型(S)到皮层亚型(C)再到典型亚型(T)成倍增加,即S-C-T模型估计每个SuStaIn亚型的危险比是前一个亚型的1.57倍(即。即皮质组的转化风险是皮质下组的1.57倍,典型组的转化风险是皮质组的1.57倍,而典型组的转化风险是皮质下组的2.46(1.572)倍)。在其余的模型中,每次只比较两组,以证明在没有这个假设的情况下,结果是相似的,尽管统计能力有所下降。这一结果表明,从SuStaIn获得的疾病亚型和分期对预测轻度认知障碍和阿尔茨海默病之间的转换都有额外的效用,亚型和分期都会修改转换的风险。统计学意义表示为。~P < 0.1, *P < 0.05, **P < 0.01, †P < 1 × 1 0-3
SuStaIn为患者分层提供了实用程序。图5说明了SuStaIn为每种神经退行性疾病提供疾病亚型和分期信息的能力。图5a显示了遗传FTD中持续性亚型的分配强度(见方法:分配给亚型的强度)随着疾病的进展而增加,88%的患者有症状GENFI中的突变携带者被强烈指定(即特定亚型的可能性>50%)。图5b显示,AD患者对持续亚型的分配强度也随着疾病的进展而增加,78%的ADNI患者被诊断为AD,个体对亚型的分配很强。坚持通过考虑时间异质性而实现的AD亚型的强烈分配与先前的研究23形成对比,这些研究建立了表型而不是时间异质性的模型。此外,即使在早期疾病阶段(MCI)也可以看到强烈的分配,在那里许多受试者聚集在三角形的顶点周围:37%的MCI受试者被强烈分配到一个亚型。图5c,d显示,在GENFI和ADNI诊断组之间,维持阶段的分布不同,并很好地分离了症状前和症状突变携带者,以及认知正常(CN)和AD。
SuStaIn亚型区分FTD基因型。表1显示了使用图2中的SuStaIn亚型来区分GENFI中受影响的突变携带者的基因型所获得的分类准确性。虽然在这些受试者中,使用磁共振成像来识别基因型是不必要的,所以在临床上没有相关性,但这个实验展示了Support在具有已知基本事实的数据集中识别亚型的能力。对于区分同质GRN和MAPT载波组的双向分类任务,持续亚型给出了95%的均衡准确率。对于更具挑战性的三向分类任务,即在存在异质性的情况下区分所有基因类型,持续亚型提供了86%的最大平衡准确率。高比例的同质性GRN和MAPT携带者被正确地分配到不对称的额叶(93%的受累GRN携带者)和颞叶亚型进展模式(91%的受累MAPT携带者)。异质性C9orf72携带者群体更难分类,总共75%的受影响C9orf72携带者被归类为额颞叶和皮质下亚型。除了异质性,C9orf72携带者也更难分类,因为额颞叶和皮质亚型进展模式与其他亚型更相似;通过评估每一对亚型进展模式的相似性(见方法:两个亚型进展模式之间的相似性),我们发现非对称额叶和颞叶亚型的进展模式在任何一对亚型中最明显;非对称额叶和额颞叶亚型的进展模式在任何一对亚型中最相似。准确地将受试者分配到亚型的策略可能会在一定程度上改变分类率,补充表1检查了这种影响。
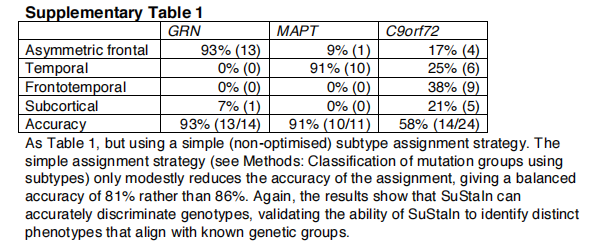
基因歧视优于只考虑亚型的模型。表2显示了用子类型模型(图6)获得的分类精度,该模型没有考虑时间异质性,以区分GENFI中受影响的突变携带者的基因。维持子类型的表现优于仅限子类型的模型。对于区分GRN和MAPT携带者组的双向分类任务,仅亚型模型的均衡准确率为92%,而对于区分GRN和MAPT携带者组的双向分类任务,使用Support的均衡准确率为95%;对于区分所有基因类型的三向分类任务,仅亚型模型的最大均衡准确率为69%,而使用Support的最大均衡准确率为86%。在仅有亚型的模型中,大多数错误分类是由于早期受影响的GRN和MAPT携带者被归类为与C9orf72携带者相关的额颞部轻度亚型。另见补充表2。
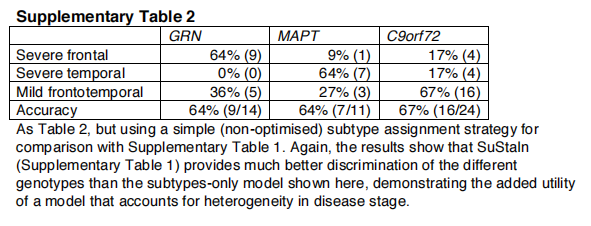
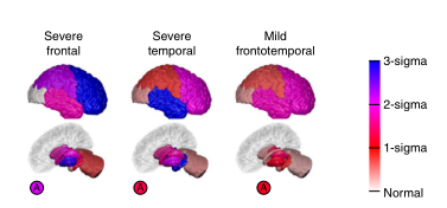
图6 GENFI的纯亚型模型;不考虑疾病阶段的异质性。脑图与图2一样,但在这里每个图代表一个不同的亚型,我们称之为严重额叶型、严重颞叶型和轻微额叶型。在仅有亚型的模式中没有疾病阶段的概念。
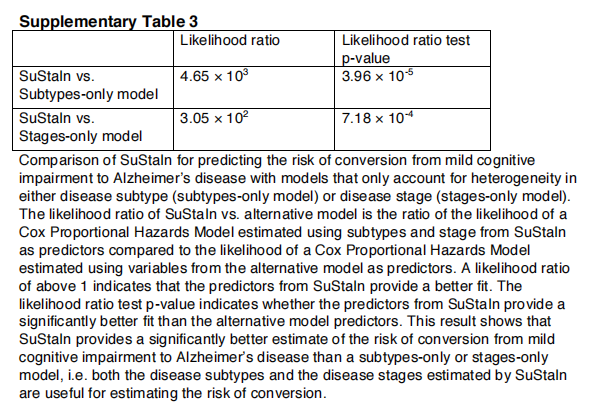
SuStaIn子类型和阶段在AD中具有预测效用。表3显示了维持子类型和阶段ADNI中诊断类别之间转换风险的预测性实用程序。通过对COX比例风险模型的拟合,我们发现基线持续亚型(p=2.44×10−3)和分期(p=8.76×10−11)对个体从轻度认知障碍转变为AD的风险有显著影响(t检验)。在维持亚型中,皮质亚型与转换风险最低相关,而典型亚型与转换风险最高相关。补充表3显示,在估计ADNI中诊断类别之间转换的风险方面,STATINE优于仅限子类型和仅限阶段的模型。通过执行似然比检验,比较只分阶段和只分阶段的模型,我们发现,分阶段模型(p=7.18×10−4)和仅分类型模型(p=3.96×10−5)相比,持续模型提供了更好的拟合(似然比检验)。这表明,维持性评估的亚型和分期都为预测从MCI向AD转化的风险提供了额外的信息。
讨论
在本研究中,我们介绍了SuStaIn,这是一种用于数据驱动的疾病表型发现的强大工具,提供了对疾病病因的洞察,并增强了临床试验和医疗保健中患者分层的能力。来自GENFI数据集的结果首次验证了SuStaIn可以成功地恢复与不同基因类型对应的遗传FTD中已知的不同进展模式。此外,IMPORT识别和表征了C9orf72基因突变携带者的组内异质性,在两个亚型中表现为不同的时间进程模式。这些结果证明了SuStaIn对于数据驱动的疾病表型发现的有效性,并提供了对C9orf72突变的生物学见解。应用3T ADNI数据集的支持恢复了三种不同的AD亚型,其最终阶段反映了死后的神经病理结果。一个基本独立的AD数据集(ADNI 1.5T)的结果证实了这三种亚型。与死后神经病理学研究3、28或其他机器学习技术23相比,疾病亚型鉴定提供了更多的东西,它表征了每一亚型的时间轨迹,使受试者能够按疾病阶段以及疾病亚型在体内分层。我们通过遗传FTD和AD的亚型和阶段证明了体内维持分层的能力。在遗传性FTD中,我们发现持续神经影像亚型能够以较高的分类准确率区分属于不同遗传群体的患病携带者。在AD中,我们证明了受试者对持续亚型的强烈赋值即使在早期疾病阶段(MCI),持续亚型和分期也增加了预测临床诊断之间转换的实用价值,而不是更传统的仅限分期或仅限亚型的模型。
以往的遗传FTD研究发现,在GRN携带者中,额顶叶体积不对称性丢失,在MAPT携带者中,颞叶体积丢失,在C9orf72携带者中,小脑广泛的对称性灰质萎缩和体积丢失24。图2中的额叶不对称亚型和颞叶亚型分别与GRN和MAPT突变携带者的区域体积丢失的研究明显相似。然而,通过避免依赖粗略的先验分期,例如通过平均家族性发病年龄,维持性提供了更多的细节和准确性。图2中的额颞叶亚型和皮质亚型都具有以前与C9orf72突变携带者相关的特征,但SuStaIn将这些特征分配给两个不同的疾病亚型,并进一步揭示了每个亚型的时间进展。
在C9orf72突变携带者中观察到的两种亚型可能是由多种生物因素单独或联合产生的。临床上,虽然有显著的重叠,但患者通常表现为行为变异型FTD或肌萎缩侧索硬化症,作为他们的主要表型31,他们可以以不同的速度进展;遗传上,扩展长度是可变的,并且有额外的遗传修饰物(例如TMEM106B和ATXN2)改变表型32-34;在病理上,大多数病例要么是A型,要么是B型TDP-43 31。虽然还需要进一步的研究来确定影响神经解剖表型的生物因素,但这些发现证明了SuStaIn在使用临床数据识别迄今未被识别的疾病亚型方面的能力,从而打开了将遗传学、病理学和神经解剖学的差异联系起来的可能性。
我们还发现了在MAPT突变携带者中存在附属群体的证据,但数量太少,无法确定该群体是否有明显的进展模式。在有明显磁共振萎缩证据的个体中(≥5的持续期),13个个体中的4个个体(来自同一家族的两对个体)被确认属于附属组。尽管MAPT突变通常被认为具有一种非常特殊的萎缩模式,主要影响前和内侧颞叶,但先前的一篇论文表明,在特定突变中可能存在第二种模式的萎缩,其中外侧颞叶受到的影响比内侧区域更大。有趣的是,在我们的分析中构成附属组的两对个体都有P301L突变,该突变属于参考文献中的第二个交替萎缩模式组35。在我们的分析中,9个被分配到主要进展模式的个体都没有P301L突变或V337M突变,这是在参考文献中发现的另一个突变。35表现为交替的萎缩模式。这表明,维持剂可能能够识别属于这一替代组的特定MAPT突变,但还需要更大规模的研究来证实这一点。
在阿尔茨海默病患者中,尸检组织学3和临近死亡时间的回顾性分析MRI扫描观察到晚期阿尔茨海默病患者有三种不同的萎缩模式:一种集中在类似于典型持续亚型晚期的颞叶;一种主要影响皮质区域。皮质支持亚型的晚期;皮质下受累较强的亚型。皮质下持续亚型的晚期。这给了人们对持续亚型的信心,这些亚型通过揭示每一亚型随时间的进展提供了更多的信息,包括区域容量损失的最早部位。此外,重要的是,为了实用,可以使用MRI在体内指定持续亚型,从而使晚期病理观察与早期神经变性联系起来。
在3T MRI数据集中发现的三种AD亚型得到了基本上独立的1.5T MRI数据集的证实。然而,在每个数据集中恢复的三个亚型的亚型进展模式之间出现了一些小的差异。这些差异主要在于伏隔核在不同亚型中开始萎缩的时间:在所有三种亚型中,3T亚型的伏隔核萎缩早于1.5T亚型。一种可能的解释是,与1.5T MRI扫描相比,使用更高的场强3T MRI扫描可以更准确地估计相对较小的伏隔核体积,因此可以从3T数据集的早期阶段识别伏隔核萎缩。在1.5T MRI数据集中,我们还发现了一小部分(4%)具有顶叶亚型的离群值。这一小亚组可能代表后脑皮质萎缩表型:比较阿尔茨海默病评估量表-认知亚量表(ADAScog)在被分配到顶亚组(N=6)和典型AD亚组(N=65)的AD诊断个体之间的得分,我们发现顶亚组在某些Praxic(Q6)上表现较差(Mann-Whitney U检验)。概念实践,p=6.1×10−3,z=2.7)和空间要求(Q14.。数字抵消,p=4.9×10−3,z=2.8)子测试,但在存储器域(Q8)中的性能相似(Mann-Whitney U检验)。单词再认,p=0.81,z=−0.2;单词回忆,p=0.48,z=0.70)。此外,顶叶亚组比典型AD亚组平均年轻10.3岁(p=2.8×10−3,z=−3.0,Mann-Whitney U检验)。
SuStaIn估计的不同亚型的时间扩散模式提供了生物学上的启示。例如,每个亚型的进展模式提供了一个观点,即神经退行性疾病如何从一个独特的起源扩散到大脑的其他部分,而这一过程不受表型异质性的影响。SuStaIn的一个关键优势是它提供了一个纯粹的数据驱动的、无假设的、关于神经退行性疾病亚型进展的重建。然而,这些观察结果也有很大的潜力为神经退行性疾病的机械模型36,37提供信息,这些模型通过各种假设的疾病传播机制在大脑网络上解释其时间进展。目前的机理模型隐含地假设了单一疾病的进展模式--这一假设在病人数据集中经常被违反,但如果专注于特定的SuStaIn亚型,则更为合理。
SuStaIn在AD患者分层方面显示出强大的能力,我们能够在遗传性FTD中验证这一点,我们期望亚型的分配能够对应于不同的基因型。SuStaIn为区分遗传性FTD的不同突变类型提供了很高的分类精度,而且AD亚型是可以明确分配的。在遗传性FTD中,SuStaIn的表现优于其他分类方法。而仅有亚型模型的平衡分类准确率为86%,而仅有亚型模型为69%。这提供了令人信服的证据,表明在不同的表型中,疾病阶段有很大的异质性,建立这种疾病阶段异质性的模型对更好地对病人进行分层很重要。这一点在AD中得到了进一步证明,在预测诊断类别之间的转换方面,SuStaIn的亚型和分期大大优于单纯亚型和单纯分期的模型。这些早期结果是非常有希望的,特别是考虑到这里使用的生物标志物的特殊选择(粗略的区域脑容量)并没有为分层进行优化。在这项初步研究中,我们选择使用MRI,以最大限度地增加具有所有可用测量值的受试者数量,简化结果的解释,并提高临床效用。然而,未来的工作将测试在SuStaIn中包括更广泛的生物标志物和更细化的区域体积对病人分层的额外好处。例如,在AD中,纳入淀粉样蛋白和神经纤维缠结的测量,如来自淀粉样蛋白和tau正电子发射断层扫描(PET),将能够在疾病的最早期阶段对个体进行分层。
张等人23之前的研究也使用了一个仅有亚型的模型来研究AD亚型的分配,该模型没有考虑疾病阶段的时间异质性。与张等人的研究相反,我们观察到AD患者对亚型的强烈分配(图5B),强调了在疾病阶段考虑异质性的重要性。这种可分配性随着疾病的进展而明显增加,在临床诊断为AD的患者中,这种亚型的分配最为强烈。然而,即使在早期(MCI),许多受试者聚集在三角形的顶点周围,显示出识别代表每个亚型的早期队列的强大潜力。
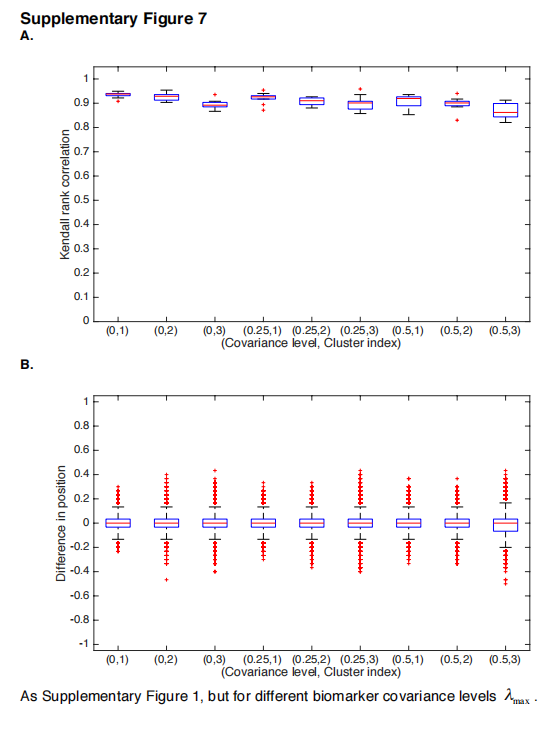
SuStaIn的基础模型做了几个假设,以便能够同时估计亚型和它们的进展情况。一个假设是,生物标志物的变化是独立的。在现实中,由于共同的生物过程,生物标志物往往是共同变化的。然而,模拟实验(补充图7)显示,SuStaIn恢复的亚型进展模式对生物标志物的协方差是稳健的。然而,完善可能来自于对强依赖性生物标志物之间的共变性进行建模,例如使用模型选择标准来确定一组最小的必要共变性参数,未来的工作将探索这一想法。
为了能够对纯粹的横断面数据进行建模,这里我们做了一个任意时间尺度的假设。当有纵向数据时,这种表述也能起作用,尽管在这里我们保留了纵向信息,以验证SuStaIn在个体首次就诊时进行未来预测的临床效用。然而,对SuStaIn的扩展,利用纵向信息进一步提供一个明确的时间尺度,是未来工作的一个重要领域。
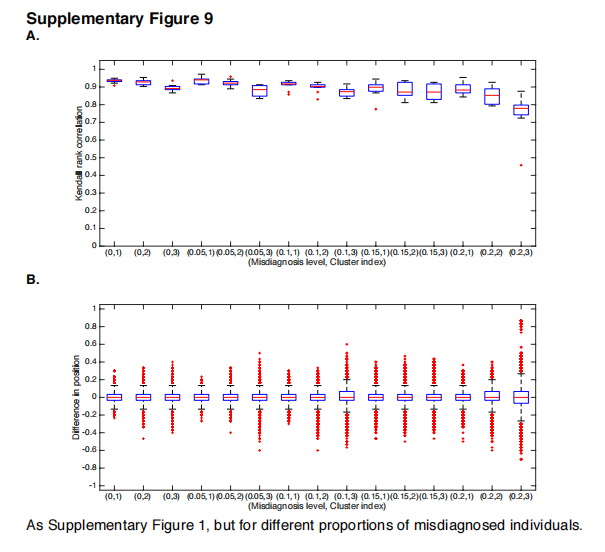
在此,我们做了一个进一步的隐含假设,即队列中的诊断是正确的。虽然GENFI的基因测试确保了这一点,但ADNI的AD临床诊断不太可靠,误诊的比例,如抑郁症或其他神经系统疾病,是不可忽视的。对误诊影响的模拟(补充图9)表明,SuStaIn可以在相当大比例的离群值下稳健地恢复亚型进展模式,最高可达20%。尽管如此,未来对SuStaIn模型的调整可能包括一个广泛的离群值类别,以捕捉不符合任何主要集群的个体。
对这些发现的一个警告是,基础数据可能来自疾病进展模式的频谱,而不是像SuStaIn所设计的那样估计一组不同的轨迹。模拟(补充图11)表明,SuStaIn仍然可以从由一系列进展模式产生的数据中恢复多种不同的进展模式。在这种情况下,SuStaIn识别的不同的进展模式仍然提供了关于进展模式的基础谱系中的极值的有用信息。然而,在这里,与遗传性FTD的基因型和AD的神经病理学观察相一致,使人们相信不同的亚型是真实的。未来的工作将扩展SuStaIn,使其能够代表进展模式的光谱(例如使用Mallow的模型,如参考文献38,39)。
我们介绍了SuStaIn--一种用于分解和描述神经退行性疾病的时间和表型异质性的工具。我们用它来阐明遗传性FTD和AD亚型的时间和表型的异质性,其细节是以前没有见过的。我们进一步证明了SuStaIn作为AD患者分层工具的潜力,它显示了即使在疾病的早期阶段,受试者与特定亚型的强烈一致性,以及预测临床诊断之间转换的额外力量。SuStaIn有潜力作为精准医疗的工具产生实质性的临床影响,并可随时适用于任何进展性疾病,包括其他神经退行性疾病、呼吸系统疾病和癌症。
方法
GENFI 数据集
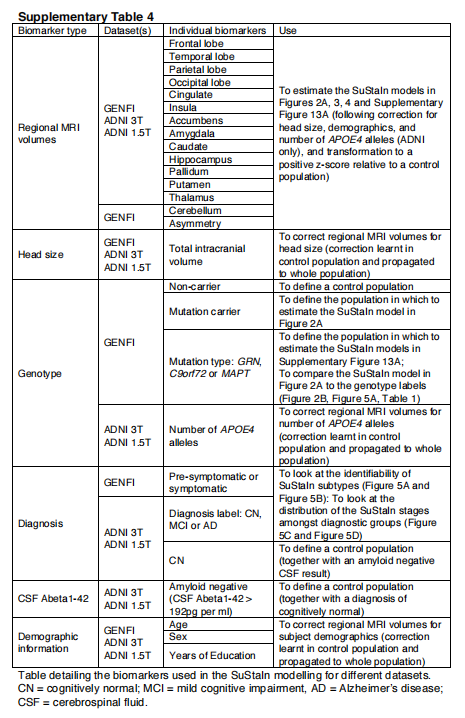
我们使用了GENFI(/)的横断面体积MRI数据。受试者来自GENFI的第二次数据冻结,总共包括365名参与者,由英国、加拿大、意大利、荷兰、瑞典和葡萄牙的13个中心招募而来。共有313名参与者有可用的体积T1加权MRI扫描用于分析(15名参与者没有扫描,其他参与者由于运动、其他成像伪影或不可能归因于FTD的病理学而导致扫描质量不合适而被排除)。这313名参与者包括141名非携带者、123名无症状携带者和49名有症状携带者。在123名无症状的突变携带者中,有62名GRN、39名C9orf72和22名MAPT携带者。在49个有症状的携带者中,有14个GRN,2 4个C9orf72和11个MAPT携带者。GENFI的采集和后处理程序已在文献29中描述。简单地说,皮层和皮层下的体积是用多图谱分割传播的方法产生的40,结合感兴趣的皮层区域来计算整个皮层的灰质体积,分成额叶、颞叶、顶叶、枕叶、扣带回和岛叶皮层。除了区域容积测量外,我们还包括一个不对称性的测量,它被计算为左右半球容积之差的绝对值,以两个半球的总容积为标准。该不对称性指标经过对数转换以提高正态性。SuStaIn建模中使用的生物标志物摘要见补充表4。
ADNI数据集
本文编写过程中使用的数据来自阿尔茨海默病神经成像倡议(ADNI)数据库(. usc.edu)。ADNI于2003年由美国国家老龄化研究所(NIA)、美国国家生物医学成像和生物工程研究所(NIBIB)、美国食品和药物管理局(FDA)、私营制药公司和非营利组织发起,是一项为期5年、耗资6000万美元的公私合作项目。最新的信息,见。我们获得了所有参与者的书面同意,并且该研究得到了每个参与机构的机构审查委员会的批准。
我们于2016年5月11日从神经成像实验室(LONI;http://adni. loni.usc.edu)下载了数据,并构建了两套用于SuStaIn模型拟合的横断面容积型MRI数据集:具有较高(3T)和较低(1.5T)场强的数据。3T和1.5T数据集的纳入标准是拥有通过整体质量控制的3T(使用FreeSurfer 5.1版处理)或1.5T(使用FreeSurfer 4.3版处理)MRI扫描的截面FreeSurfer体积。3T数据集包括793名受试者(183名CN,86名明显的记忆问题,243名早期MCI,164名晚期MCI,117名AD),其中73人被列入ADNI-1,99人被列入ADNI-GO,621人被列入ADNI-2。1.5T数据集由576名ADNI-1受试者组成(180名CN,274名晚期MCI,122名AD)。1.5T和3T数据集基本上是独立的:只有59名受试者(14名CN,33名晚期MCI,12名AD)同时拥有1.5T和3T扫描。我们使用FreeSurfer 4.3和5.1版本下载了1.5T和3T扫描的横断面FreeSurfer卷,并进行了质量控制评级。我们只保留了通过整体质量控制的体积,并通过对颅内总体积进行回归来实现其正常化。我们进一步下载了人口统计学用于协变量校正的信息:年龄、性别、教育和ADNIMERGE表中的APOE基因型。我们下载了诊断随访信息,以测试SuStaIn模型亚型和阶段与纵向结果的关联。我们还下载了Aβ1-42的基线脑脊液(CSF)测量值,我们用它来确定对照人群。同样,SuStaIn模型中使用的生物标志物摘要见补充表4。
z-scores。在GENFI中,我们使用了所有非携带者的数据;在ADNI中,我们使用了淀粉样蛋白阴性的CN受试者,定义为那些CSF Aβ1-42测量值>192 pg/ml41。这样我们就得到了3T数据集的48个淀粉样蛋白阴性的CN受试者的对照组,以及1.5T数据集的56个淀粉样蛋白阴性的CN受试者。我们用这些对照组来确定年龄、性别、教育程度或APOE4等位基因的数量(仅ADNI)的影响是否显著,如果是,则将它们回归出来。然后我们将每个数据集相对于其对照组进行归一化处理,使对照组的平均值为0,标准差为1。由于区域脑容量随着时间的推移而减少,Z值会随着疾病的发展而变成负值,所以为了简单起见,我们取Z值的负值,这样Z值会随着脑容量的异常而增加。
SuStaIn的建模。我们将SuStaIn的基础模型表述为具有不同生物标志物演变模式的受试者群体(见数学模型)。我们把具有特定生物标志物进展模式的一组受试者称为亚型。每个亚型的生物标志物演变被描述为一个线性Z-分数模型,其中每个生物标志物在一个共同的时间框架内遵循一个片状线性轨迹。每个生物标志物的噪声水平在时间范围内被假定为恒定的,并来自于一个对照组(见数学模型)。这个线性Z-score模型是基于文献中基于事件的模型。7,8,38,但重新表述了事件,使其代表生物标志物从一个z-core到另一个z-core的连续线性累积,而不是从正常水平到异常水平的瞬间转换。这种表述的一个关键优势是它可以与纯粹的横断面数据一起工作,因为它不需要关于变化的时间尺度的信息,而是把事件作为具有任意持续时间的分片线性段的控制点。模型拟合考虑了越来越多的子类型C,为此我们估计了属于每个子类型的受试者的比例f,以及每个子类型c=1...C的生物标志物达到每个z分数的顺序SC。
数学模型。支撑的线性z-Score模型是最初基于事件的模型7、8的连续推广,我们首先描述该模型。
模型拟合。补充图15提供了流程图,详细说明了维持性模型拟合中涉及的过程。模型拟合需要同时优化子类型成员数、子类型轨迹以及两者的后验分布。具体地说,这里的成本函数取决于序列排序,据我们所知,标准算法不能处理这一点。因此,我们基于为基于事件的模型(7,8,42,43)开发的成熟方法,推导出我们自己的算法来适应维护,我们在模拟(参见补充结果:收敛)和在本文使用的数据集(参见收敛)中展示了收敛和最优性。如补充图15中的黑框所示,维持模型是分层拟合的,通过交叉验证获得的模型选择标准来估计聚类的数量。分层拟合从先前的C-1-簇模型初始化每个C-簇(子类型)模型的拟合,即,从C=1…顺序地解决聚类问题。CMAX(其中Cmax是要安装的最大簇数),使用先前的模型初始化每个模型。对于初始聚类(C=1),我们使用补充图15中绿色框中所示的单聚类期望最大化(E-M)过程,并在后面进行描述。我们通过使用补充图15中蓝色框中所示的拆分集群E-M过程生成C-1个候选C集群模型来分层拟合后续集群编号(C>1),并在下文中进行描述。从这些C-1候选C-簇模型中,选择似然最高的模型。
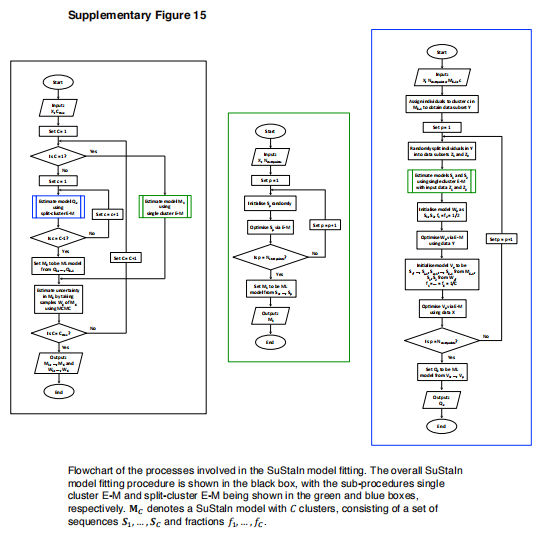
使用补充图15中蓝色框中所示的拆分集群E-M过程来生成每个C-1候选C集群模型。对于C-1个群中的每一个,分裂群E-M过程首先找出群c分成两个群的最佳分裂。为了找到将簇C分成两个簇的最佳分割,属于簇C的数据点被随机分配给两个单独的簇。然后使用单群E-M过程(补充图15中的绿色框)获得这两个数据子集的最优模型参数。这些集群参数用于使用E-M来初始化两个集群模型与属于集群c的数据子集的拟合。然后,将该两簇解决方案与其他C-2簇一起使用,以初始化C簇模型的拟合。然后使用E-M来优化C-簇模型,在更新每个簇的序列SC和分数Fc之间交替。对25个不同的起始点(随机簇分配)重复此过程,以找到最大似然解(请参阅收敛)。
补充图15中绿色框中所示的单群E-M过程用于寻找单群的最佳模型参数(生物标志物达到每个z分数的序列S)。在单簇E-M过程中,序列S被随机初始化。然后,通过依次遍历每个z分数事件E并找到其在序列中相对于其他z分数事件的最佳位置,即通过固定子序列T=S/E的顺序并通过改变事件e在子序列T中的位置来最大化序列的可能性,来优化该序列。序列S被更新,直到收敛。再一次,单簇序列S从25不同的随机起始序列来寻找最大似然解(参见收敛)。
融合 在模型拟合的几个点上,我们从许多不同的起点执行贪婪的优化,并选择最大似然序列或序列集。多重运行保护,防止局部极小值。然而,事实上,我们发现优化表现出良好的收敛:从所有起点开始的运行通常收敛到一个解,其似然度在最大似然的1×10−3%以内,并且在不确定性估计过程估计的不确定性内(参见不确定性估计)。在(补充结果:收敛)中使用合成数据的模拟进一步证明了维持算法的收敛和定位全局最小值和正确解的能力。
不确定性估计。除了估计每个子类型的最可能序列SC之外,我们还可以通过评估每个可能序列的概率来确定每个子类型的所有序列的相对似然。这给了我们对排序SC中的不确定性的估计,我们通过绘制每个z得分事件出现在每个子类型的序列中的每个位置的概率来总结该不确定性。我们使用不同的颜色来可视化该概率(例如,参见图2)以指示每个区域已经达到特定z分数的累积概率:区域从z分数0-sigma到1sigma的累积概率范围从白色的0到1(红色),区域从z分数1-sigma到2-sigma的累积概率从红色的0到1(洋红色),以及区域从z-分数2-sigma到3sigma的累积概率从洋红色的0到蓝色的1。在实践中,序列的数量太大,无法估计所有可能的序列,所以我们使用马尔可夫链蒙特卡罗(MCMC)抽样来提供这种不确定性的近似,如文献7,8。7,8,我们取从最大似然解初始化的1,000,000个MCMC样本,检查MCMC迹显示出良好的混合特性。
交叉验证。我们在这里使用十重交叉验证有两个不同的目的:(I)评估子类型的最佳数量和(Ii)评估子类型进展模式的一致性。我们使用交叉验证信息准则(CVIC)44来评估子类型的最佳数量,即通过评估来自c=1…的每个c子型模型的可能性。C,并在所有折叠中选择具有最高的样本外似然P(X|M)或相当于最低的CVIC值的模型。CICC定义为CICC=−2×LOG(P(X|M)),其中P(X|M)是数据对于特定维持模型M的概率,即P(X|M)=1 P(X|Sc)P(Sc)。在较复杂模型的证据不强的情况下(各模型的CICC与最小CICC之间的差异小于6,或同等情况下各模型的样本外对数似然与最小样本外对数似然之间的差异小于3),我们倾向于较不复杂的模型,以避免过度拟合45。为了评估子类型进展模式的一致性,我们执行了十次交叉验证,将数据分成十个折叠,并将模型重新拟合到每个数据子集,其中一个折叠保留用于每次测试。我们通过计算两个子类型的进展模式之间的相似性(参见两个子类型进展模式之间的相似性)来报告跨折叠的模型的一致性:适合每个折叠的模型和适合整个数据集的模型。
两个亚型进展模式之间的相似性。为了能够比较数据子集(补充图13B)和交叉验证折叠(图2-4中的CVS,以及补充图13A和14)中的子类型进展模式,我们使用Bhattacharyya系数46来测量子类型进展模式对的相似性。我们评估了两个亚型进展模式中每个生物标记物事件的位置之间的Bhattacharyya系数,该系数在生物标记物事件和MCMC样本中平均。Bhattacharyya系数衡量生物标志物事件在亚型序列中位置分布的相似性,范围从0(最大相异度)到1(最大相似性)。
患者分型和分期。我们将受试者分配到由维持模型(图5,表1和3)预测的子类型和阶段,方法是首先评估他们属于每个子类型的可能性(通过在疾病阶段上积分),并选择可能性最高的子类型,然后评估他们属于最可能子类型的每个阶段的概率,并选择可能性最高的阶段。在评估似然性时,我们对MCMC样本集进行积分,以说明模型参数中的不确定性,而不是仅评估最大似然参数处的似然。这意味着患者的模型阶段指示给定数据的序列的后验分布上的平均位置。
对子类型赋值的强度。我们通过比较个体处于≤2期的概率(即,他们没有重大的影像异常,因此不能被分配到特定的亚型)和他们属于每个持续亚型的概率(每个亚型的概率相加在3+期)来评估个体分配给特定亚型的强度。分配的强度被评估为他们属于其中一个亚型的最大概率。我们认为那些有最大概率属于一个超过一半的特定亚型的人被认为具有较强的亚型赋值。
与仅限子类型和仅限阶段的模型进行比较。我们将我们的支持模型与仅限子类型的模型和仅限阶段的模型进行了比较。在仅有亚型的模型中,个体根据其生物标记物测量的相似性被聚为一组--而不考虑疾病阶段的异质性。仅分期模型是一种疾病进展模型,其中所有受试者都被假定为单一共同进展模式的样本--而不考虑疾病亚型的异质性。我们制定了仅限亚型和仅限阶段的模型,以便它们尽可能地接近维持模型,但不分别建模疾病阶段或疾病亚型的异质性。这使我们能够评估在维持模型中考虑疾病阶段或亚型异质性的益处。仅限子类型的模型由均值和方差未知的高斯混合模型组成。仅亚型模型适用于GENFI的症状性突变携带者和ADNI的AD受试者,因此这些亚型对应于单个诊断组。正如对维持模型所做的那样,我们使用CVIC44评估了最佳集群(子类型)的数量。仅阶段模型是数学模型中描述的维持模型的一个特例,其中只对一个子类型进行建模,即C=1.
GENFI数据集的SuStaIn模型。补充表4-6汇总了维护算法的设置。我们对GENFI数据集的不同亚组进行了支持建模:全部172个突变携带者,76个GRN突变携带者,63个C9orf72突变携带者,33个MAPT突变携带者。对于所有突变携带者,我们建立了最多5个亚型的维持模型。对于GRN、C9orf72和MAPT突变携带者,我们建立了最多3个亚型的维持模型。我们为GENFI数据集选择了z分数事件,以包括每个卷的z分数1、2和3,但排除了z分数事件,其中少于10个突变携带者的值大于该z分数。根据最大z分数事件是1、2还是3,分别将在进程的最后阶段达到的最大z分数设置为2、3或5。我们在每个GENFI实验中保持相同的z得分事件。
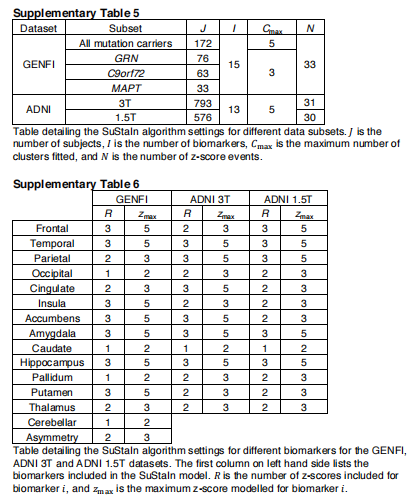
ADNI数据集的SuStaIn建模。我们对ADNI数据集的两个基本独立的(由59个人组成)子组应用了持续建模:793个人进行了3T MRI扫描,576人进行了1.5T MRI扫描,我们测试了最多5个亚型的维持模型。就像我们对GENFI所做的那样,我们选择了z得分事件来包括每卷的z得分1、2或3,但排除了z得分事件,其中只有不到10名受试者的值大于那个z得分。同样,根据最大z分数事件分别是1、2或3,将在进展的最后阶段达到的最大z分数设置为2、3或5。可在补充表4-6中找到维持算法设置的全部细节。
使用亚型对突变组进行分类。我们进行了两个实验,以比较从持续模型和仅亚型模型获得的亚型将GENFI中的突变携带者分类到不同突变组的能力。在第一个实验(表1和表2)中,我们优化了分配给每个子类型所需的概率。这解释了不同亚型中不同数量的异质性。在第二个实验(补充表1和2)中,我们简单地将个体分配到他们最可能的亚型,并将他们分配的亚型与他们的突变组进行比较。在这两个实验中,分类结果被报告为通过10倍交叉验证获得的样本外精度。
数据可用性 本研究中使用的遗传FTD数据将通过GENFI网站(),并向GENFI数据访问委员会提出申请(电子邮件:genfi@ucl)。Ac.uk)。这项研究中使用的AD数据来自阿尔茨海默病神经成像倡议(ADNI)数据库(adni.Loni.usc.edu)。可在上获得维护源代码
参考文献:
Young AL, Marinescu RV, Oxtoby NP,et al. Uncovering the heterogeneity and temporal complexity of neurodegenerative diseases with Subtype and Stage Inference. Nat Commun. 2018 Oct 15;9(1):4273.
原文链接: style="margin: 0px;padding: 0px;box-sizing: border-box;">点击“阅读原文”,可跳转至原文链接